Performance:SURF
Comparison of SURF implementations
The SURF descriptor is a state-of-the-art image region descriptor that is invariant with regard to scale, orientation, and illumination. By using an integral image, the descriptor can be computed efficiently across different scales. In recent years it has emerged as one of the more popular and frequently-used feature descriptors, but it is not a trivial algorithm to implement, and several different implementations exist. The following study compares several different libraries to determine relative stability and runtime performance.
Tested Implementations:
| Implementation | Version | Language | Threaded | Comment |
|---|---|---|---|---|
| BoofCV | alpha v0.1 | Java | No | http://www.boofcv.org/ Fast but less accurate. See FactoryDescribeRegionPoint.surf() |
| BoofCV-M | alpha v0.1 | Java | No | http://www.boofcv.org/ Accurate but slower. See FactoryDescribeRegionPoint.surfm() |
| OpenSURF | 27/05/2010 | C++ | No | http://www.chrisevansdev.com/computer-vision-opensurf.html |
| Reference | 1.0.9 | C++ | No | http://www.vision.ee.ethz.ch/~surf/ |
| JOpenSURF | SVN r24 | Java | No | http://code.google.com/p/jopensurf/ |
| JavaSURF | SVN r4 | Java | No | http://code.google.com/p/javasurf/ |
| OpenCV | 2.3.1 SVN r6879 | C++ | No [1] | http://opencv.willowgarage.com/wiki/ |
| Pan-o-Matic | 0.9.4 | C++ | No | http://aorlinsk2.free.fr/panomatic/?p=home |
[1] OpenCV can be configured to use multi-threaded code if it is compiled with IPP. In this test that was not done so it is single threaded.
Benchmark Source Code:
Questions or Comments about this study?
Post those here: https://groups.google.com/group/boofcv
Conclusions
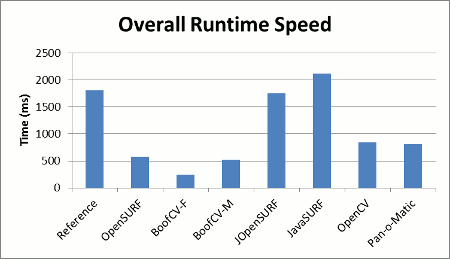
|
| Figure 1: Runtime performance comparison for detecting and describing. Single 850x680 pixel image and 2000 features. Lower is better. |
|---|
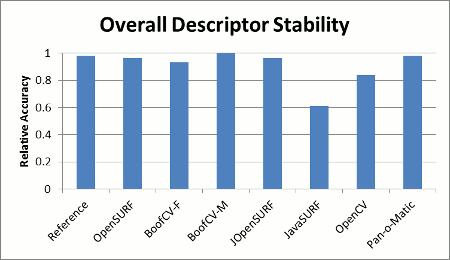 |
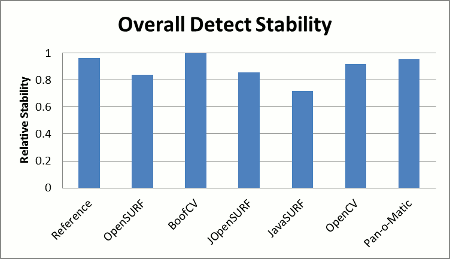
|
| Figure 2: Overall region descriptor stability comparison. Scores are relative to the best library. Higher is better. | Figure 3: Overall stability of interest point detection. Scores are relative to the best library. Higher is better. |
|---|
For the sake of those with short attention spans, the summary results are posted first and a discussion of testing methodology follows. Figure 1 shows how fast each library could select and describe interest points. Figures 2 and 3 shows a summary of each implementation's relative describe and detect stability across a standard set of test images.
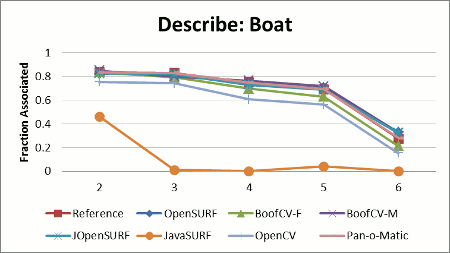
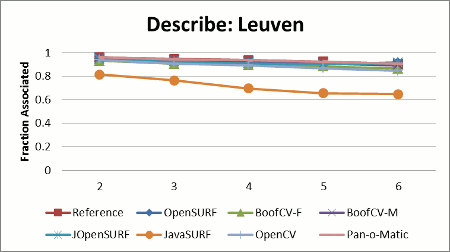
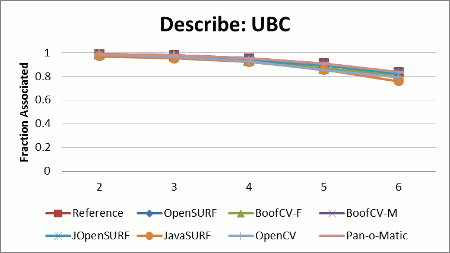
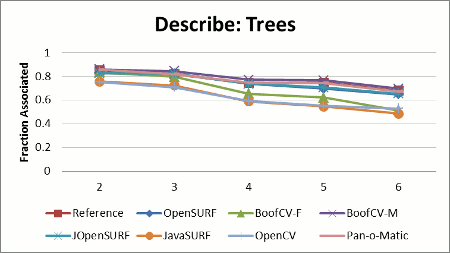
One reason for JavaSURF's poor stability is that it only implements an upright version of SURF, so rotated images defeat the descriptor. Not computing orientation helps JavaSURF on the runtime benchmark, because it has fewer computations to perform. JOpenSURF is a straightforward port of the OpenSURF library to Java and shows comparable stability with the expected hit on runtime performance. JOpenSURF, OpenSURF and BoofCV-M all compute an enhanced version of the SURF descriptor, while BoofCV and OpenCV descriptors are closer to the SURF paper. I suspect that the descriptor computed by the reference library is also an improvement over what was presented in the SURF paper, but the source code is closed, so this theory cannot be directly verified.
OpenCV is a bit of an oddball library as far as SURF is concerned. It did not provide an interface that would allow it to be tested in the same manner as the other libraries, and comments in the code indicated that parts of it are multi-threaded using IPP. However, OpenCV was not compiled with IPP turned on so only a single thread was used. Because of these issues, OpenCV's own interest points were used instead of the precomputed ones when testing stability.
BoofCV's speed is due to algorithmic changes and code optimization. A new technique for orientation estimation was used in "BoofCV" but not "BoofCV-M", accounting for a large speed boost at the cost of a slight loss in stability. Special optimized code was used for features entirely inside the image, counter acting Java's poor loop unrolling.
Descriptor Stability
- Images from evaluation data set

Graffiti Sequence

Boat Sequence

Trees Sequence

Bricks Sequence




The stability benchmark was performed using standardized test images from [1], which have known transformations. Stability was measured based on the number of correct associations between two images in the data set. The testing procedure for each library is summarized below:
- For each image, detect features (scale and location) using the fast Hessian detector in BoofCV.
- Save results to a file and use the same file for all libraries.
- For each image, compute a feature description (including orientation) for all features found.
- In each image sequence, associate features in the first image to the Nth image, where N > 1.
- Association is done by minimizing Euclidean error.
- Validation is done using reverse association, i.e. the association must be the optimal association going from frame 1 to N and N to 1.
- Compute the number of correct associations.
- An association is correct if it is within 3 pixels of the true location.
Since the transformation is known between images, the true location could have been used. However, in reality features will not lie at the exact point, and a descriptor needs to be tolerant of this type of error. Thus, this is a more accurate measure of the descriptor's strength in real-world data.
Stability results shown in Figure 2 display the relative stability across all test images for each library. Relative stability is computed by summing up the total percent of correctly associated features across the whole test data set, and then choosing the library with the best performance. The relative stability is computed by dividing each library's score by the best performer's score.
Configuration: All libraries were configured to describe oriented SURF-64 features as defined in the original SURF paper. JavaSURF does not support orientation estimation. OpenCV forces orientation to be estimated inside the feature detector; therefore it was decided that the lesser evil would be to let OpenCV detect its own features. OpenCV's threshold was adjusted so that it detected about the same number of features.
Stability Results
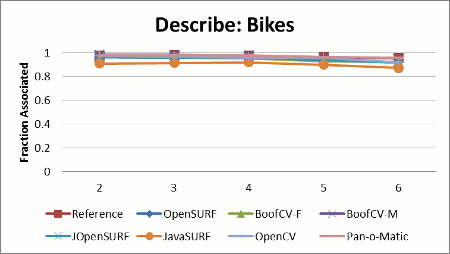 |
|
 ] ] |
|
 |
|
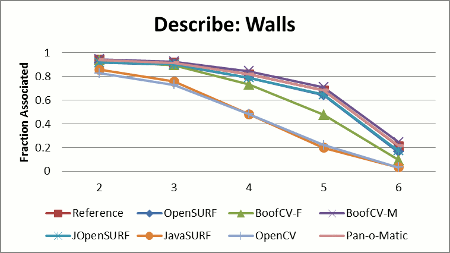 |
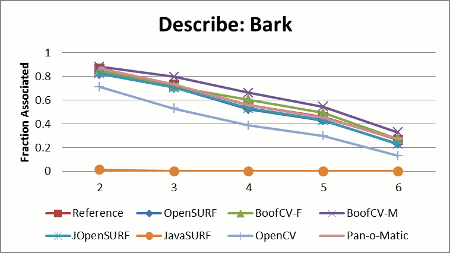
|
Detection Stability
SURF feature points are typically detected using the fast Hessian detector described in the SURF feature. Each library provided its own implementation of the fast Hessian detector. Interest point detection stability refers to how well an interest's point location and scale is detect after the image has undergone a transformation. A perfect detector would detect a point in the same location as it was in the original image after applying the image transform.
Performance was measured based upon the fraction of the total features detected in the first image which had a corresponding interest point detected in the later images. Two interest points were said to correspond if their location and scales were both within tolerance. The expected location and scale was computed using the known transformations. Scale was computed by sampling four evenly spaced points one pixel away from an interest point in the first frame. The known transform was then applied to each point and the change in distance measured. The expected scale was set to the average distance each point was from transformed interest point location.
When compiling the results it was noticed that libraries which detected more features always scored better when using the just mentioned metric. It was also noted that a poorly behaving detector could score highly in the just mentioned metric. For example if every pixel was marked as an interest point or if densely packed clusters were returned as detected features. One of the libraries even had a known bug were false positives would be returned near the image border.
To compensate for these issues, only interest points were considered if they were an unambiguous match and the detection threshold was tuned to return the same number of features for at least one image. A match was declared as ambiguous if more than one interest point was found to be close to the expected interest point location.
Library Configurations:
- Tune detection threshold to detect about 2000 features in graffiti image 1
- Only consider a 3x3 non-max region
- Octaves: 4
- Scales: 4
- Base Size: 9
- Initial Pixel Skip: 1
Performance Calculation:
- Detect interest points in all images
- Transform interest points in image 1 to image N
- For each interest point in image 1:
- Find all interest points in image N within 1.5 pixels and 25% of the expected scale.
- If the expected pixel location is outside the image, ignore.
- If the number of matches is more than one, ignore.
- If the number of matches is one, mark the interest point as a correct detection.
- Count number of valid interest points which have zero or one matches.
- Detection metric for each image in the sequence is the total number of correct detections divided by the number of valid interest points.
The summary chart is generated by summing up the detection metric for each library across all the images and then dividing each library's score by the library with the best score.
Runtime Speed
 |
|
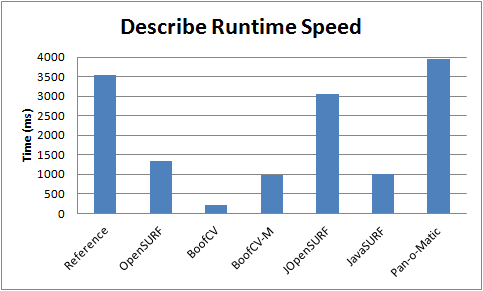
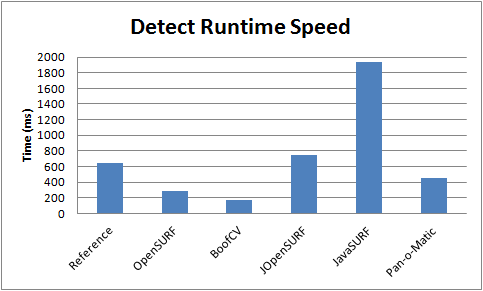
| Figure 4: Describe runtime performance using 6415 precomputed interest points. Lower is better. | Figure 5: Detect runtime performance. 850x680 image. Lower is better. |
|---|
Each library's speed in describing and detecting was individually benchmarked (Figures 4,5) and benchmarked together (Figure 2). Each test was performed five times, but only the best time is shown. Java libraries tended to exhibit more variation than native libraries, although all libraries showed a significant amount of variation from trial to trial.
Only image processing time essential to SURF was measured, not image loading time. Time to convert the gray scale image into an integral image was measured, but not the time to convert the image to grayscale. Even if these image processing tasks were included, they would only account for a small fraction of the overall computation time. Elapsed time was measured in the actual application using System.currentTimeMillis() in Java and clock() in C++.
Testing Procedure for Describe:
- Kill all extraneous processes.
- Load feature location and size from file.
- Compute descriptors (including orientation) for each feature while recording elapsed time.
- Compute elapsed time 10 times and output best result.
- Run the whole experiment 5 times for each library and record the best time.
Similar procedures were follows for detect and the combined benchmark.
Test Computer:
- Ubuntu 10.10 64bit
- Quadcore Q6600 2.4 GHz
- Memory 8194 GB
- g++ 4.4.5
- Java(TM) SE Runtime Environment (build 1.6.0_26-b03)
Compiler and JRE Configuration:
- All native libraries were compiled with -O3
- Java applications were run with no special flags
Describe Specific Setup:
- input image was boat/img1
- Fast Hessian features from BoofCV
- 6415 Total
Detect Specific Setup:
- Impossible to configure libraries to detect exact same features
- Adjusted detection threshold to top out at around 2000 features
- Octaves: 4
- Scales: 4
- Base Size: 9
- Initial Pixel Skip: 1
All (describe and detect) Specific Setup:
- Same as detect setup
Comments: OpenCV was omitted from individual detect and describe benchmarks because the two tasks could not be decoupled in the same way as the other libraries. Both BoofCV and BoofCV-M use the same detector which is why only BoofCV is listed in the detector results.
Change History
- November 14, 2011
- Added detect stability results
- November 12, 2011
- Added Pan-o-Matic to overall results