Example Scene Classification
From BoofCV
Jump to navigationJump to search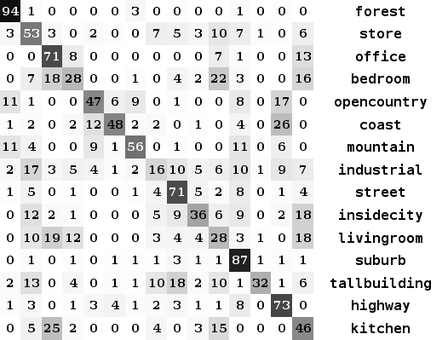
Confusion matrix created from the code below. Perfect results would be black along the diagonal.

Scene classification is the problem where you are presented with an image and you need to classify it as belonging to a known set. The example below demonstrates how to perform scene classification using dense SURF features and a nearest neighbour classifier. See code documentation for a more detailed discussion.
Example Code:
Concepts:
- Scene Classification
- Dense Image Features
- Clustering
- k-NN classifier
Related Examples:
Example Code
/**
* <p>
* Example of how to train a K-NN bow-of-word classifier for scene recognition. The resulting classifier
* produces results which are correct 52.2% of the time. To provide a point of comparison, randomly selecting
* a scene is about 6.7% accurate, SVM One vs One RBF classifier can produce accuracy of around 74% and
* other people using different techniques claim to have achieved around 85% accurate with more advanced
* techniques.
* </p>
*
* Training Steps:
* <ol>
* <li>Compute dense SURF features across the training data set.</li>
* <li>Cluster using k-means to create works.</li>
* <li>For each image compute the histogram of words found in the image</li>
* <li>Save word histograms and image scene labels in a classifier</li>
* </ol>
*
* Testing Steps:
* <ol>
* <li>For each image in the testing data set compute its histogram</li>
* <li>Look up the k-nearest-neighbors for that histogram</li>
* <li>Classify an image by by selecting the scene type with the most neighbors</li>
* </ol>
*
* <p>NOTE: Scene recognition is still very much a work in progress in BoofCV and the code is likely to be
* significantly modified in the future.</p>
*
* @author Peter Abeles
*/
public class ExampleClassifySceneKnn extends LearnSceneFromFiles {
// Tuning parameters
public static int NUMBER_OF_WORDS = 100;
public static boolean HISTOGRAM_HARD = true;
public static int NUM_NEIGHBORS = 10;
public static int MAX_KNN_ITERATIONS = 100;
// Files intermediate results are stored in
public static final String CLUSTER_FILE_NAME = "clusters.obj";
public static final String HISTOGRAM_FILE_NAME = "histograms.obj";
// Algorithms
ClusterVisualWords cluster;
DescribeImageDense<GrayU8, TupleDesc_F64> describeImage;
NearestNeighbor<HistogramScene> nn;
ClassifierKNearestNeighborsBow<GrayU8, TupleDesc_F64> classifier;
public ExampleClassifySceneKnn( final DescribeImageDense<GrayU8, TupleDesc_F64> describeImage,
ComputeClusters<double[]> clusterer,
NearestNeighbor<HistogramScene> nn ) {
this.describeImage = describeImage;
this.cluster = new ClusterVisualWords(clusterer, 0xFEEDBEEF);
this.nn = nn;
}
/**
* Process all the data in the training data set to learn the classifications. See code for details.
*/
public void learnAndSave() {
System.out.println("======== Learning Classifier");
// Either load pre-computed words or compute the words from the training images
AssignCluster<double[]> assignment;
if (new File(CLUSTER_FILE_NAME).exists()) {
assignment = UtilIO.load(CLUSTER_FILE_NAME);
} else {
System.out.println(" Computing clusters");
assignment = computeClusters();
}
// Use these clusters to assign features to words
var featuresToHistogram = new FeatureToWordHistogram_F64(assignment, HISTOGRAM_HARD);
// Storage for the work histogram in each image in the training set and their label
List<HistogramScene> memory;
if (!new File(HISTOGRAM_FILE_NAME).exists()) {
System.out.println(" computing histograms");
memory = computeHistograms(featuresToHistogram);
UtilIO.save(memory, HISTOGRAM_FILE_NAME);
}
}
/**
* Extract dense features across the training set. Then clusters are found within those features.
*/
private AssignCluster<double[]> computeClusters() {
System.out.println("Image Features");
// Compute features in the training image set
var features = new ArrayList<TupleDesc_F64>();
for (String scene : train.keySet()) {
List<String> imagePaths = train.get(scene);
System.out.println(" " + scene);
for (String path : imagePaths) {
GrayU8 image = UtilImageIO.loadImage(path, GrayU8.class);
describeImage.process(image);
// the descriptions will get recycled on the next call, so create a copy
for (TupleDesc_F64 d : describeImage.getDescriptions()) {
features.add(d.copy());
}
}
}
// add the features to the overall list which the clusters will be found inside of
for (int i = 0; i < features.size(); i++) {
cluster.addReference(features.get(i));
}
System.out.println("Clustering");
// Find the clusters. This can take a bit
cluster.process(NUMBER_OF_WORDS);
UtilIO.save(cluster.getAssignment(), CLUSTER_FILE_NAME);
return cluster.getAssignment();
}
public void loadAndCreateClassifier() {
// load results from a file
List<HistogramScene> memory = UtilIO.load(HISTOGRAM_FILE_NAME);
AssignCluster<double[]> assignment = UtilIO.load(CLUSTER_FILE_NAME);
var featuresToHistogram = new FeatureToWordHistogram_F64(assignment, HISTOGRAM_HARD);
// Provide the training results to K-NN and it will preprocess these results for quick lookup later on
// Can use this classifier with saved results and avoid the
classifier = new ClassifierKNearestNeighborsBow<>(nn, describeImage, featuresToHistogram);
classifier.setClassificationData(memory, getScenes().size());
classifier.setNumNeighbors(NUM_NEIGHBORS);
}
/**
* For all the images in the training data set it computes a {@link HistogramScene}. That data structure
* contains the word histogram and the scene that the histogram belongs to.
*/
private List<HistogramScene> computeHistograms( FeatureToWordHistogram_F64 featuresToHistogram ) {
List<String> scenes = getScenes();
List<HistogramScene> memory;// Processed results which will be passed into the k-NN algorithm
memory = new ArrayList<>();
for (int sceneIndex = 0; sceneIndex < scenes.size(); sceneIndex++) {
String scene = scenes.get(sceneIndex);
System.out.println(" " + scene);
List<String> imagePaths = train.get(scene);
for (String path : imagePaths) {
GrayU8 image = UtilImageIO.loadImage(path, GrayU8.class);
// reset before processing a new image
featuresToHistogram.reset();
describeImage.process(image);
for (TupleDesc_F64 d : describeImage.getDescriptions()) {
featuresToHistogram.addFeature(d);
}
featuresToHistogram.process();
// The histogram is already normalized so that it sums up to 1. This provides invariance
// against the overall number of features changing.
double[] histogram = featuresToHistogram.getHistogram();
// Create the data structure used by the KNN classifier
HistogramScene imageHist = new HistogramScene(NUMBER_OF_WORDS);
imageHist.setHistogram(histogram);
imageHist.type = sceneIndex;
memory.add(imageHist);
}
}
return memory;
}
@Override
protected int classify( String path ) {
GrayU8 image = UtilImageIO.loadImage(path, GrayU8.class);
return classifier.classify(image);
}
public static void main( String[] args ) {
var surfFast = new ConfigDenseSurfFast(new DenseSampling(8, 8));
// ConfigDenseSurfStable surfStable = new ConfigDenseSurfStable(new DenseSampling(8,8));
// ConfigDenseSift sift = new ConfigDenseSift(new DenseSampling(6,6));
// ConfigDenseHoG hog = new ConfigDenseHoG();
DescribeImageDense<GrayU8, TupleDesc_F64> desc =
FactoryDescribeImageDense.surfFast(surfFast, GrayU8.class);
// FactoryDescribeImageDense.surfStable(surfStable, GrayU8.class);
// FactoryDescribeImageDense.sift(sift, GrayU8.class);
// FactoryDescribeImageDense.hog(hog, ImageType.single(GrayU8.class));
var configKMeans = new ConfigKMeans();
configKMeans.maxIterations = MAX_KNN_ITERATIONS;
configKMeans.reseedAfterIterations = 20;
ComputeClusters<double[]> clusterer = FactoryClustering.kMeans_MT(
configKMeans, desc.createDescription().size(), 200, double[].class);
clusterer.setVerbose(true);
// The _MT tells it to use the threaded version. This can run MUCH faster.
int pointDof = desc.createDescription().size();
NearestNeighbor<HistogramScene> nn = FactoryNearestNeighbor.exhaustive(new KdTreeHistogramScene_F64(pointDof));
ExampleClassifySceneKnn example = new ExampleClassifySceneKnn(desc, clusterer, nn);
var trainingDir = new File(UtilIO.pathExample("learning/scene/train"));
var testingDir = new File(UtilIO.pathExample("learning/scene/test"));
if (!trainingDir.exists() || !testingDir.exists()) {
String addressSrc = "http://boofcv.org/notwiki/largefiles/bow_data_v001.zip";
File dst = new File(trainingDir.getParentFile(), "bow_data_v001.zip");
try {
DeepBoofDataBaseOps.download(addressSrc, dst);
DeepBoofDataBaseOps.decompressZip(dst, dst.getParentFile(), true);
System.out.println("Download complete!");
} catch (IOException e) {
throw new UncheckedIOException(e);
}
} else {
System.out.println("Delete and download again if there are file not found errors");
System.out.println(" " + trainingDir);
System.out.println(" " + testingDir);
}
example.loadSets(trainingDir, null, testingDir);
// train the classifier
example.learnAndSave();
// now load it for evaluation purposes from the files
example.loadAndCreateClassifier();
// test the classifier on the test set
Confusion confusion = example.evaluateTest();
confusion.getMatrix().print();
System.out.println("Accuracy = " + confusion.computeAccuracy());
// Show confusion matrix
// Not the best coloration scheme... perfect = red diagonal and blue elsewhere.
ShowImages.showWindow(new ConfusionMatrixPanel(
confusion.getMatrix(), example.getScenes(), 400, true), "Confusion Matrix", true);
// For SIFT descriptor the accuracy is 54.0%
// For "fast" SURF descriptor the accuracy is 52.2%
// For "stable" SURF descriptor the accuracy is 49.4%
// For HOG 53.3%
// SURF results are interesting. "Stable" is significantly better than "fast"!
// One explanation is that the descriptor for "fast" samples a smaller region than "stable", by a
// couple of pixels at scale of 1. Thus there is less overlap between the features.
// Reducing the size of "stable" to 0.95 does slightly improve performance to 50.5%, can't scale it down
// much more without performance going down
}
}